Many languages offer a facility for allowing one source code file to gain access to other source files. Although JavaScript files can be included from within an HTML page (using the HTML ‘<script>’ element with an appropriate ‘src’ attribute), JavaScript itself has no capability for including one JavaScript source file from another.
In this article, I’ll take a first look at developing such a feature, along with possible future developments of the facility.
Update: JavaScript Include, Part 2 article has now been published.
Further update: JavaScript Include, Part 3 article has now been published.
Disclaimer
It may seem like a strange thing to admit at this stage, but JavaScript isn’t really my thing. Although I’ve tinkered with JavaScript for many years, it’s been a rather on-and-off affair, and somewhat more off than on. Because of this, please prefix everything I say here with something like ‘As far as I can tell…’ or ‘It seems to me…’ or equivalent.
I have tried to make a reasonable attempt to avoid writing garbage, but please do feel free to constructively comment on any misconceptions or other gaffes I might have made.
What’s Include?
In short, I’m aiming to produce a feature that would allow the JavaScript developer to use something like the following within their JavaScript code:
include("useful.js");
After such a directive, all code within ‘useful.js’ (functions or what have you) would be available for use.
As JavaScript doesn’t support such a feature, there’s a Catch-22: If we were to be able to develop the code to provide an ‘include()’ facility, how would a JavaScript source file be able to gain access to it when there’s no way to include other JavaScript source code?
There are only two ways I can think of to proceed (if you can think of others, do let me know):
- Every JavaScript source file must contain a copy of the code to provide ‘include()’, or
- Every HTML page (or page template) must contain an appropriate ‘<script>’ element to ‘include’ the separate ‘include()’ source file (‘include.js’, say).
Out of the two, the second seems the least bad to me. It’s likely that JavaScript is almost exclusively used as part of web developments, so JavaScript code only gets to run because it’s invoked, in one way or another, from a web page.
Assuming that you feel okay about adding a line like the following to each of your web pages (or templates), then we’re on our way:
<script type="text/javascript" src="include.js"></script>
How to Implement Include
Using JavaScript, it’s possible to add ‘<script>’ elements programmatically to the current document, something like this:
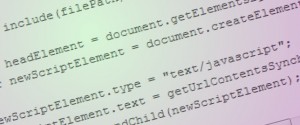
// A first attempt at 'include()'.
function include(filePath)
{
var headElement = document.getElementsByTagName("head")[0];
var newScriptElement = document.createElement("script");
newScriptElement.type = "text/javascript";
newScriptElement.src = filePath;
headElement.appendChild(newScriptElement);
}
This function will kind of work, but there’s a problem. In general, JavaScript interpreters (such as the one built into your browser) try to load web content asynchronously, so the loading of the file named by ‘filePath’ above will be handled separately from the execution of the ‘include()’ code. This means that the named file won’t necessarily have been loaded by the time the ‘include()’ function returns. So, if the included file contains a ‘usefulFn()’ function, for example, calling it as follows may result in an error indicating that the function has not been found:
include("useful.js");
usefulFn();
The asynchronous loading of separate files can, it seems, be sidestepped by writing a copy of the included code into the body of the ‘<script>’ element itself, something like this (this line to be used instead of the ‘newScriptElement.src’ line in the first attempt):
newScriptElement.text = "function usefulFn() { alert('usefulFn'); }";
Therefore, it seems as if all we need to do is replace the literal string of code in this last line with a bit of JavaScript to read the contents of the file to be included and assign it to ‘newScriptElement.text’, and we’re there… However, JavaScript hasn’t traditionally been keen to allow you to read files at all, and even now that file handling support has been included as part of HTML5, such facilities are geared up to working with files asynchronously… so it would seem that we’re back to Square 1.
We’re so close, though. All we need is some way to synchronously read file contents, and, fortunately, AJAX provides a means:
var req = new XMLHttpRequest();
req.open("GET", filePath, false); // 'false': synchronous.
req.send(null);
// All being well, content of 'filePath' now in 'req.responseText'.
When you ask how to read a file (or, indeed, do anything) synchronously, pretty much all self-respecting JavaScript programmers will ask you why you want to do it before they reveal the answer (assuming they reveal it at all). This is because JavaScript is generally asynchronous for a reason. After all, nothing stops a loading website in its tracks quicker than trying to synchronously read a file from a remote server that’s not there at the moment. However, with care (used only on relatively small, local files, for example), synchronous operation can sometimes represent a good solution to a problem.
We now have pretty much all we need to have a go at producing a proper ‘include’ implementation.
Proper Implementation of Include
So far, the code presented has been pared down (with no error checking or other fail-safes) and somewhat fragmentary. Here’s an attempt to put the principles together into something more comprehensive and sturdy; an example ‘include.js’:
// Essentially 'new XMLHttpRequest()' but safer.
function newXmlHttpRequestObject()
{
try
{
if (window.XMLHttpRequest)
{
return new XMLHttpRequest();
}
// Ancient version of IE (5 or 6)?
else if (window.ActiveXObject)
{
return new ActiveXObject("Microsoft.XMLHTTP");
}
throw new Error("XMLHttpRequest or equivalent not available");
}
catch (e)
{
throw e;
}
}
// Synchronous file read. Should be avoided for remote URLs.
function getUrlContentsSynch(url)
{
try
{
var xmlHttpReq = newXmlHttpRequestObject();
xmlHttpReq.open("GET", url, false); // 'false': synchronous.
xmlHttpReq.send(null);
if (xmlHttpReq.status == 200)
{
return xmlHttpReq.responseText;
}
throw new Error("Failed to get URL contents");
}
catch (e)
{
throw e;
}
}
function include(filePath)
{
var headElement = document.getElementsByTagName("head")[0];
var newScriptElement = document.createElement("script");
newScriptElement.type = "text/javascript";
newScriptElement.text = getUrlContentsSynch(filePath);
headElement.appendChild(newScriptElement);
}
Once this has been placed into its own file, it can be referred to in your pages/templates in the same way as any JavaScript source file, e.g.:
<script type="text/javascript" src="include.js"></script>
Are There Any Problems?
As it stands, yes. If I were to ‘include()’ a source file from within another included source file, I’d want and generally expect to be using a directory path that’s relative to where the including source file resides. For example, if I were to keep all my JavaScript source in the ‘http://www.example.com/js’ directory on my site, then, within ‘js/include1.js’, I would want to use the following call to include ‘js/include2.js’:
include("include2.js"); // Relative to the including source file.
However, if ‘js/include1.js’ was itself included from ‘http://www.example.com/index.html’, then the paths passed to ‘include()’ would have to be relative to that page in order to work, i.e.:
include("js/include2.js"); // Relative to the original including page.
This means that, unless you keep all your pages and source files in one directory (which I’m sure you don’t, and wouldn’t want to), JavaScript source files would need to know the directory in which the including page resides in order to get the relative pathnames to other source files right. This isn’t ideal: What if the source file is included from two pages residing in different directories, for example?
What About Include-Once?
In addition to include, many languages offer an include-once facility. Where many files are variously dependent upon other files and upon each other, it’s easy to see how the same files could be included repeatedly. Include-once would prevent such multiple inclusions of the same file by only including each file the first time it’s encountered.
From the caller’s point of view, an include-once feature would be similar to using ‘include()’, e.g.:
includeOnce("useful.js");
usefulFn();
Including Local Files
For security reasons, some browsers (and it’s amazing that it’s not all browsers) won’t allow the reading of files using the ‘file:///’ protocol in AJAX. If you’re having difficulties (specifically seeing messages like ‘XMLHttpRequest cannot load file:///…’ in your JavaScript console), you’ll need to access the code via HTTP, i.e., via the use of a web server, instead of just double-clicking your example pages (or equivalent means of quickly loading them into your browser).
Future Articles
It is currently my intention both to present a solution to the relative pathname issue, and to write about an implementation of ‘includeOnce()’ in future articles.
Update: JavaScript Include, Part 2 article has now been published.
Further update: JavaScript Include, Part 3 article has now been published.