In this second article about developing a JavaScript ‘include’ facility, I’ll deal with the handling of inclusion paths so that included source files can include other source code using paths that are relative to themselves, rather than relative to the page containing the ‘<script>’ element that made the ‘include()’ code available initially. (If you’ve not seen the previous article or you need a reminder, please take a look at my first JavaScript ‘include’ article.)
Update: JavaScript Include, Part 3 article has now been published.
Disclaimer
Please see my JavaScript disclaimer in the first JavaScript ‘include’ article. It still applies, and constructive comments are welcome on any gaffes or oversights.
What’s Wrong With Include So Far?
As described in my first JavaScript ‘include’ article, the first attempt to implement a JavaScript ‘include’ facility suffered an issue with handling directory paths to (and within) included files. In summary:
If I were to ‘include()’ a source file from within another included source file, I’d want and generally expect to be using a directory path that’s relative to where the including source file resides. For example, if I were to keep all my JavaScript source in the ‘http://www.example.com/js’ directory on my site, then, within ‘js/include1.js’, I would want to use the following call to include ‘js/include2.js’:
include("include2.js"); // Relative to the including source file.
However, if ‘js/include1.js’ was itself included from ‘http://www.example.com/index.html’, then the paths passed to ‘include()’ would have to be relative to that page in order to work, i.e.:
include("js/include2.js"); // Relative to the original including page.
This means that, unless you keep all your pages and source files in one directory (which I’m sure you don’t, and wouldn’t want to), JavaScript source files would need to know the directory in which the including page resides in order to get the relative pathnames to other source files right. This isn’t ideal: What if the source file is included from two pages residing in different directories, for example?
What we need to do, then, is to come up with a way for the ‘include()’ function to be able to keep track of the relative positions of included source files without the including (or included) files needing to worry about the details.
Keeping Track of Paths
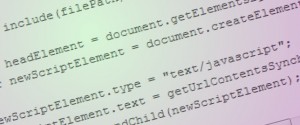
Here’s the original implementation of ‘include()’:
function include(filePath)
{
var headElement = document.getElementsByTagName("head")[0];
var newScriptElement = document.createElement("script");
newScriptElement.type = "text/javascript";
newScriptElement.text = getUrlContentsSynch(filePath);
headElement.appendChild(newScriptElement);
}
As you can see, the function as it stands takes whatever path is passed to it and uses it as-is. If we wish to allow included source files to use paths that are relative to their own location, ‘include()’ will need to keep track of the paths used for file inclusions (in order to be able to work out where included files are within a directory structure) and appropriately adjust the paths that are subsequently supplied if those included files ‘include()’ further files themselves.
For example, if a source file is included using the path ‘js/include1.js’, the ‘include()’ function will need to remember the ‘js/’ bit just in case the included ‘include1.js’ file itself calls ‘include()’ with a path that’s relative to itself. In this case, if ‘include1.js’ uses ‘include(“include2.js”)’, the ‘include()’ function should be adding the saved-up ‘js/’ prefix in order to find the ‘include2.js’ source file that ‘include1.js’ seems to believe is sitting in the same directory as itself.
If (for a further example) ‘include1.js’ uses ‘include(“../more_js/include3.js”)’, the ‘include()’ function will need to add the ‘../more_js/’ bit onto the ‘js/’ path it currently has stored (resulting in ‘js/../more_js/’) so that it knows where ‘include3.js’ is just in case that file in turn includes something else.
This is a all a little bit fiddly, but hopefully you can follow the principle of what ‘include()’ will need to be able to do.
As you might guess, using absolute paths when calling ‘include()’ changes things a little. As we’ve discussed, when a relative path is used, ‘include()’ will need to append it onto previous pathnames used in order to keep track of where the include operations have taken us so far (as we did a moment ago when ‘../more_js/’ was appended onto ‘js/’). However, at any point an absolute path is used in an ‘include()’, then that should replace the ‘include()’ function’s idea of what the path-so-far is to be.
So, where are we now? We need ‘include()’ to be able to keep a track of what pathnames have been used so far; it will do this by appending relative paths as it goes, and replacing the current path when an absolute path is used. This means we’ll need a way to determine when an absolute path is used, and we’ll need some code that can strip the pathname part of a supplied path (if any) from its base filename (e.g., work out that ‘../more_js/’ is the pathname part of ‘../more_js/include3.js’). Here are implementations of two functions to handle those two requirements:
function isAbsolutePath(filePath)
{
if (filePath.substr(0, 1) == "/" || filePath.substr(0, 7) == "http://")
{
return true;
}
return false;
}
function getAllButFilename(filePath)
{
return filePath.substr(0, filePath.lastIndexOf("/") + 1);
}
We also need somewhere for ‘include()’ to keep track of the pathname prefix to use. For this purpose, I’m going to use a global variable called ‘_includePath’. (The leading underscore is just to reduce the chances of name clashes. Globals, eh? One is being used in this case, though, so that ‘include()’ won’t need to have any additional arguments; ones that I wouldn’t want its users to have to deal with, or even know about.)
With that additional global and our two new helper functions, we could add the following code to our current ‘include()’ to do the actual work:
function include(filePath)
{
// Keep a safe copy of the current include path.
var includePathPrevious = _includePath;
if (isAbsolutePath(filePath) == true)
{
var actualPath = filePath;
// Absolute paths replace.
_includePath = getAllButFilename(filePath);
}
else
{
var actualPath = _includePath + filePath;
// Relative paths combine.
_includePath += getAllButFilename(filePath);
}
// ...
// Original 'include()' code here, but using 'actualPath'.
// ...
// Restore the include path safe copy.
_includePath = includePathPrevious;
}
… And, well, that’s all there is to it. (Unless, with my usual caveat, there’s something I haven’t thought of, which I’m counting on you to point out…)
The New ‘include()’ in Full
Here’s the new ‘include’ facility implementation with all the new bits added:
var _includePath = "";
// Essentially 'new XMLHttpRequest()' but safer.
function newXmlHttpRequestObject()
{
try
{
if (window.XMLHttpRequest)
{
return new XMLHttpRequest();
}
// Ancient version of IE (5 or 6)?
else if (window.ActiveXObject)
{
return new ActiveXObject("Microsoft.XMLHTTP");
}
throw new Error("XMLHttpRequest or equivalent not available");
}
catch (e)
{
throw e;
}
}
// Synchronous file read. Should be avoided for remote URLs.
function getUrlContentsSynch(url)
{
try
{
var xmlHttpReq = newXmlHttpRequestObject();
xmlHttpReq.open("GET", url, false); // 'false': synchronous.
xmlHttpReq.send(null);
if (xmlHttpReq.status == 200)
{
return xmlHttpReq.responseText;
}
throw new Error("Failed to get URL contents");
}
catch (e)
{
throw e;
}
}
function include(filePath)
{
// Keep a safe copy of the current include path.
var includePathPrevious = _includePath;
if (isAbsolutePath(filePath) == true)
{
var actualPath = filePath;
// Absolute paths replace.
_includePath = getAllButFilename(filePath);
}
else
{
var actualPath = _includePath + filePath;
// Relative paths combine.
_includePath += getAllButFilename(filePath);
}
var headElement = document.getElementsByTagName("head")[0];
var newScriptElement = document.createElement("script");
newScriptElement.type = "text/javascript";
newScriptElement.text = getUrlContentsSynch(actualPath);
headElement.appendChild(newScriptElement);
// Restore the include path safe copy.
_includePath = includePathPrevious;
}
function isAbsolutePath(filePath)
{
if (filePath.substr(0, 1) == "/" || filePath.substr(0, 7) == "http://")
{
return true;
}
return false;
}
function getAllButFilename(filePath)
{
return filePath.substr(0, filePath.lastIndexOf("/") + 1);
}
If you’re beginning to wish that JavaScript had its own built-in include capability, then let me assure you that I was thinking the very same thing about two articles ago.
Are We Nearly There Yet?
Well, if we’re still of the opinion that having include-once functionality could be useful (for more details about this see the first JavaScript ‘include’ article), then there’s work still left to do, but I’ll leave that for a future article.
Update: JavaScript Include, Part 3 article has now been published.
One reply on “JavaScript Include, Part 2”
[…] JavaScript Include, Part 2 article has now been […]